
Journey Start
My directed study was approved recently. The topic is about teaching A.I. mimic classical paintings such as Van Gogh, Monet etc. We briefly discussed current research of SFU iVizLab on this topic and visualized some of the generated results which are quite different to what I previously studied.
Deep Learning
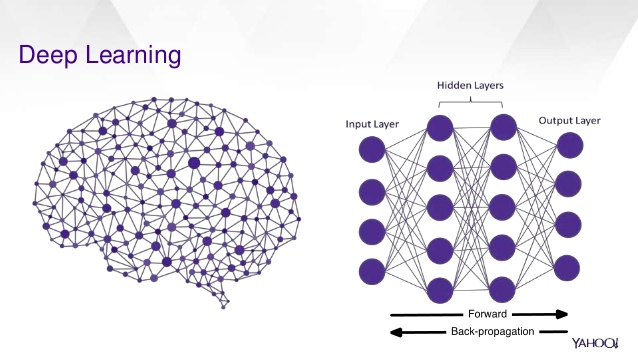
In our research, deep learning is applied extensively. It consists of decision-making with the multilayer of nodes. One example from above figure can be “Identify Animals”. The first set of four nodes at left which is the first layer can have some very primitive questions, each answer of the question is a vertex between first layer node and second layer nodes. The last layer is the final answer which is what animal is this image represented. The weight of each vertex can vary to decide how accurate the answer from the previous question is. For example, questions can be as follows:
- First Layer
- The image has color?
- The image has clear intensity change?
- The image contains limited noises?
- The image is in a reasonable size?
- Second Layer
- The image contains liquid structure like water?
- The image contains column structure like legs?
- The image subject is small?
- The image subject has fur texture?
- Third Layer
- The image contains many leg structures?
- The image contains what pattern on the fur texture?
- The image contains eye structure?
- The image contains nose structure?
- Fourth Layer
- The image is a portrait of a fish
- The image is a portrait of an elephant
- The image is a portrait of a dog
- The image is a portrait of an insect
In this case, A.I. can answer these questions by layer. Positive answer of the image has no leg and the scene is about water may lead to the fish final answer while the image has a large subject with four legs may lead to elephant answer. Once the A.I. is trained, it can be asked to create a new creature. A fish-like new creature is much likely to live underwater and without leg based on the training experience. Apply this analogy to painting, to paint like Van Gogh, the A.I. is much likely to select the stroke and style where appears in the Van Gogh paintings. This is different than synthesis one image from another one since the A.I. is using its trained knowledge to create new things rather than patching from the old ones.
Source Input Quality Matter
When human artist paint a portrait, the painting is mixed with 1.) the actual appearance of the subject and 2.) the interpretation of the artist of the subject. However, since A.I. is less capable of understanding the subject, it generally treats everything equally. Thus, some flaw from the scene, like lack of ideal lighting condition, will be captured by A.I. where the human artist can auto correct it when painting.
Segmentation of Subject from Background
Similiar to the previous section, A.I. tends to treat everything in the scene equally. Thus, current A.I. is able to generate high-quality art creation but the subject and the background are all painted artistically. In an ideal setup, the subject should be more focused rather than the background. My reflection on this is a depth map can be generated from the scene based on perspective projection. Then subject can be separated from it. However, we currently use a different approach in iVizLab which I will be covered later.
Where Human is Looking At
To resolve the problem that A.I. is difficult to separate the subject from the background, one approach is focusing on the area where the human attention is usually at. In this case, the A.I. is trained on a special data to allow it predicts if a scene is displayed to a human, where the human will look at most. In general, where the human attention is at is usually the subject or area the artist want to stress. This experiment is done by the help of eye-tracking system.
Not Enough Training Data
One thing special of this research field is usually an artist will only leave so few works through his/her life. Thus, an A.I. cannot be trained efficiently with all these limited examples. One approach we introduce to resolve this problem is training the A.I. by patches from the painting rather than the entire one. In this case, a painting can generate hundreds of 256×256 patches or more if randomness is introduced. Then, the A.I. can be sufficiently trained. However, one problem is if the training is based on patches, the A.I. tends to paint the scene less based on the overall style of the artist which lead to other problems. My reflection is since we are essentially training the A.I. how to mimic a painting style rather than create a new painting style, why not interview the people who are good at fake other artist’s painting?